Author
Kirsten Pleskot
The processor in the device you’re reading this article on almost certainly has more than one core. Multiple cores in the processor give the operating system the ability to run multiple processes at once. Sometimes, however, the programmer themselves wants to use multiple cores, so they ask the system for another execution thread and give it work to do. And depending on the programmer’s skills, the program will now either run faster, run at the same speed, be stuck in a deadlock, or behave unexpectedly due to a race condition.
In this blog post, I’ll introduce you to the basics of the C pthread API and tell you something about synchronization data structures.
Threads are names for physical cores in the processor that can execute code simultaneously.
The most important thing is to understand the concept that they do work at the same time.
Threads simply work and by default don’t share much information about what they’re currently doing.
Let’s show this with the following example.
This program creates two additional threads that will print a message 5 times while the main thread prints "Main Thread".
(The main thread is the most important core of the process which, when it finishes, causes the system to automatically terminate all other cores regardless of whether they’ve completed their work)
// import the pthreads library
#include <pthread.h>
#include <stdio.h>
// function prints message 10 times
void *print_message_function(void *ptr) {
for (int i = 0; i < 5; i++) {
printf("%s\n", (char *)ptr /* we receive the argument in our function as a void pointer
(a pointer that points to data of unknown size),
but printf expects a pointer to char,
so we must cast the pointer */);
}
// return null pointer
return NULL;
}
int main() {
pthread_t thread1, thread2;
char *message1 = "Thread 1";
char *message2 = "Thread 2";
// Here we create two threads that will start executing the function
// print_message_function
// first argument is a pointer where the thread handle will be stored
// second argument doesn't concern us today
// third argument is a pointer to the function we want the thread to execute
// fourth argument is a pointer to the data we want to pass to the function
// function returns 0 if everything went well, for this small program I'm
// discarding the value
pthread_create(&thread1, NULL, print_message_function, (void *)message1);
pthread_create(&thread2, NULL, print_message_function, (void *)message2);
// here the main core does some work
for (int i = 0; i < 5; i++) {
printf("Main Thread\n");
}
// pthread_join is a function that blocks until the given thread completes its work
pthread_join(thread1, NULL);
pthread_join(thread2, NULL);
return 0;
}The output of this program will look something like this:
Thread 1
Thread 2
Thread 2
Thread 1
Thread 1
Thread 1
Thread 1
Main Thread
Main Thread
Main Thread
Main Thread
Main Thread
Thread 2
Thread 2
Thread 2or like this:
Main Thread
Main Thread
Thread 1
Thread 1
Thread 1
Thread 1
Thread 1
Main Thread
Main Thread
Main Thread
Thread 2
Thread 2
Thread 2
Thread 2
Thread 2Or completely differently, because it depends on how the timing of which thread is doing what happens to work out.
Let’s look at a slightly different example.
#include <pthread.h>
#include <stdio.h>
int count = 0;
void *inc_count(void *arg) {
int i;
// add 100,000 to counter one by one
for (i = 0; i < 100000; i++) {
count++;
}
return NULL;
}
int main() {
pthread_t t1, t2;
// create threads
pthread_create(&t1, NULL, inc_count, NULL);
pthread_create(&t2, NULL, inc_count, NULL);
// wait for threads to complete their work
pthread_join(t1, NULL);
pthread_join(t2, NULL);
// print the counting result
// The result will surely be 200000 when two threads add 100,000
printf("count = %d\n", count);
return 0;
}The result of this program won’t be count = 200000 because the individual threads overwrite each other’s results.
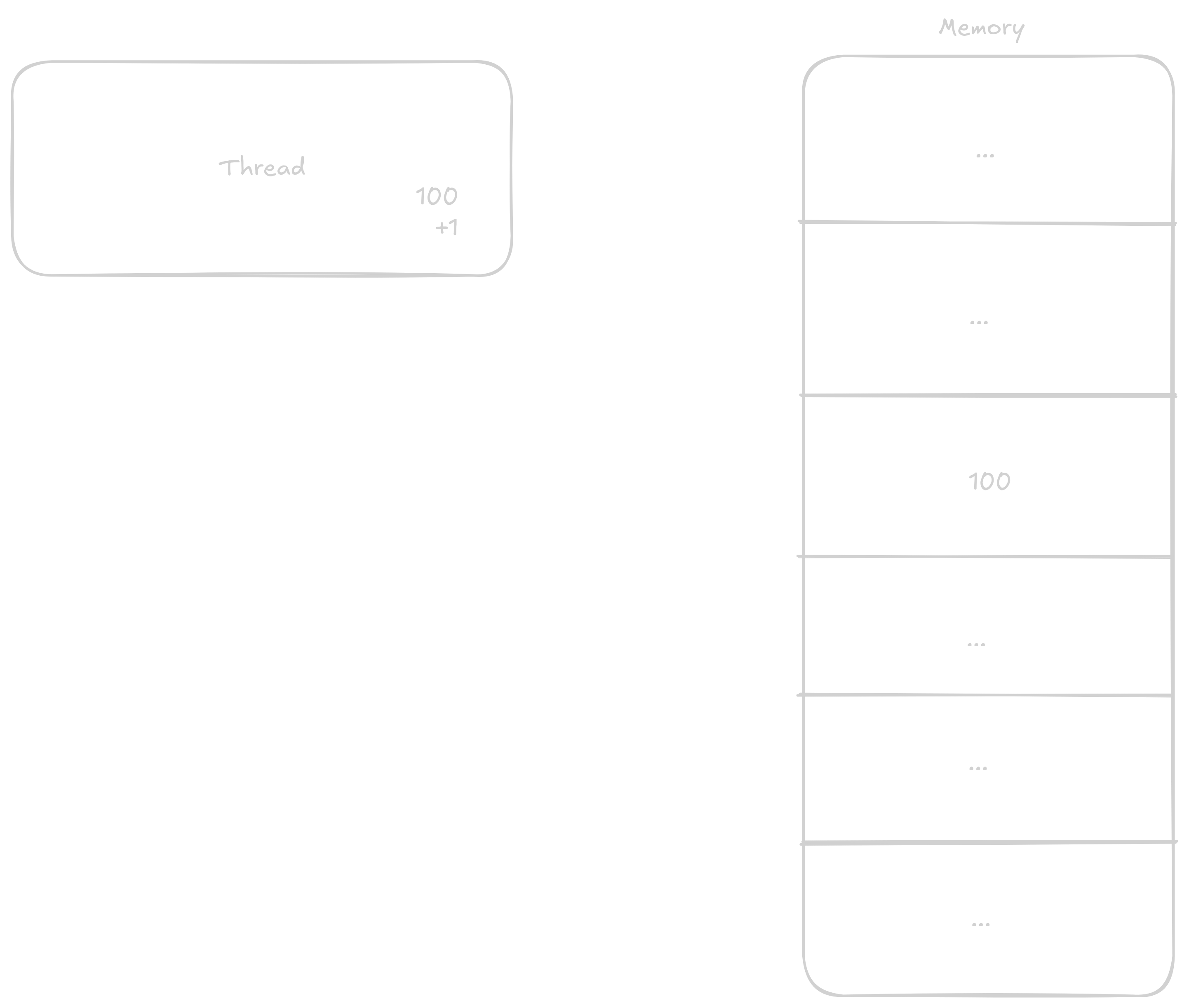
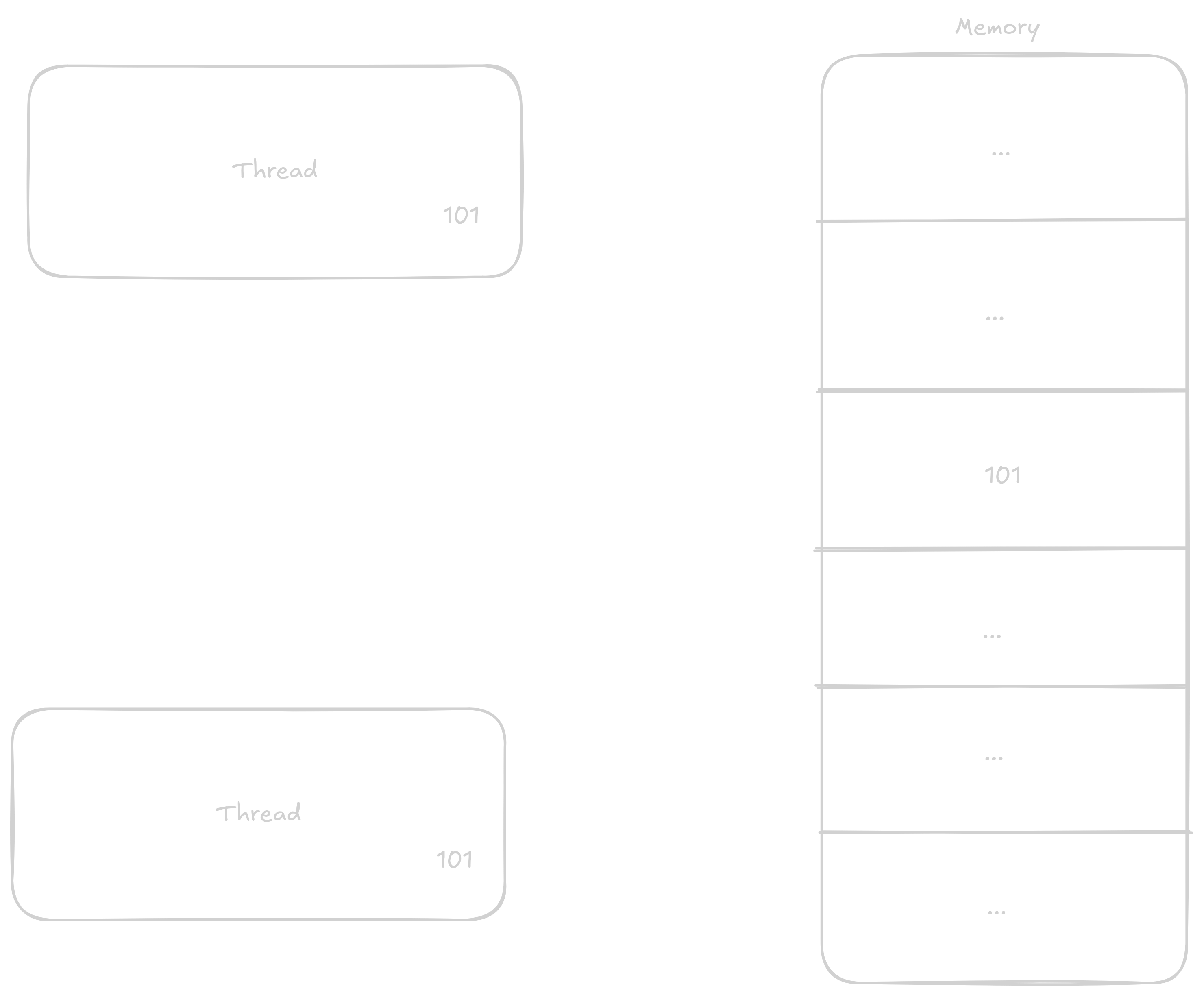
Normally when a thread wants to add 1 to a number, it proceeds in these steps:
1 to it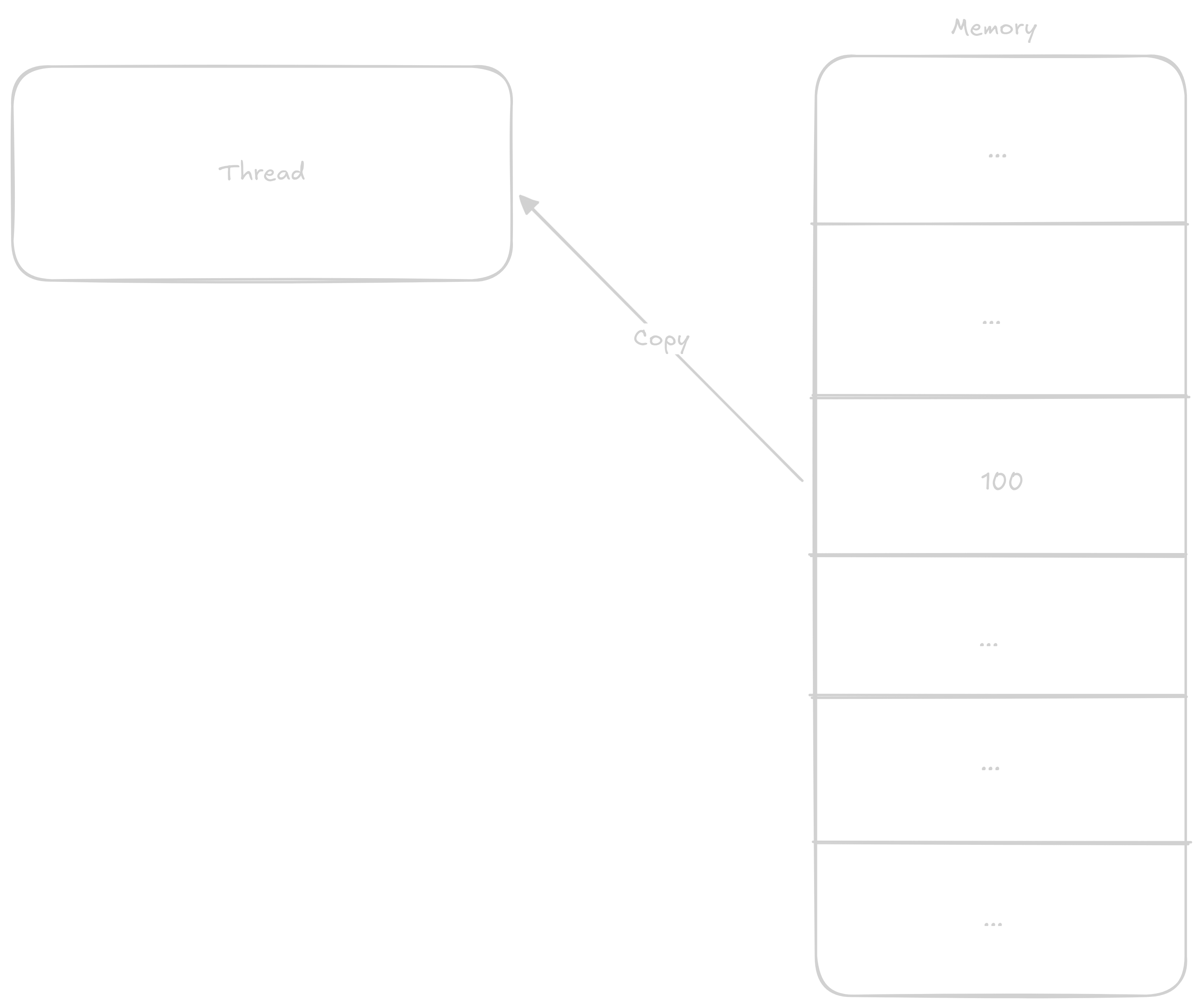
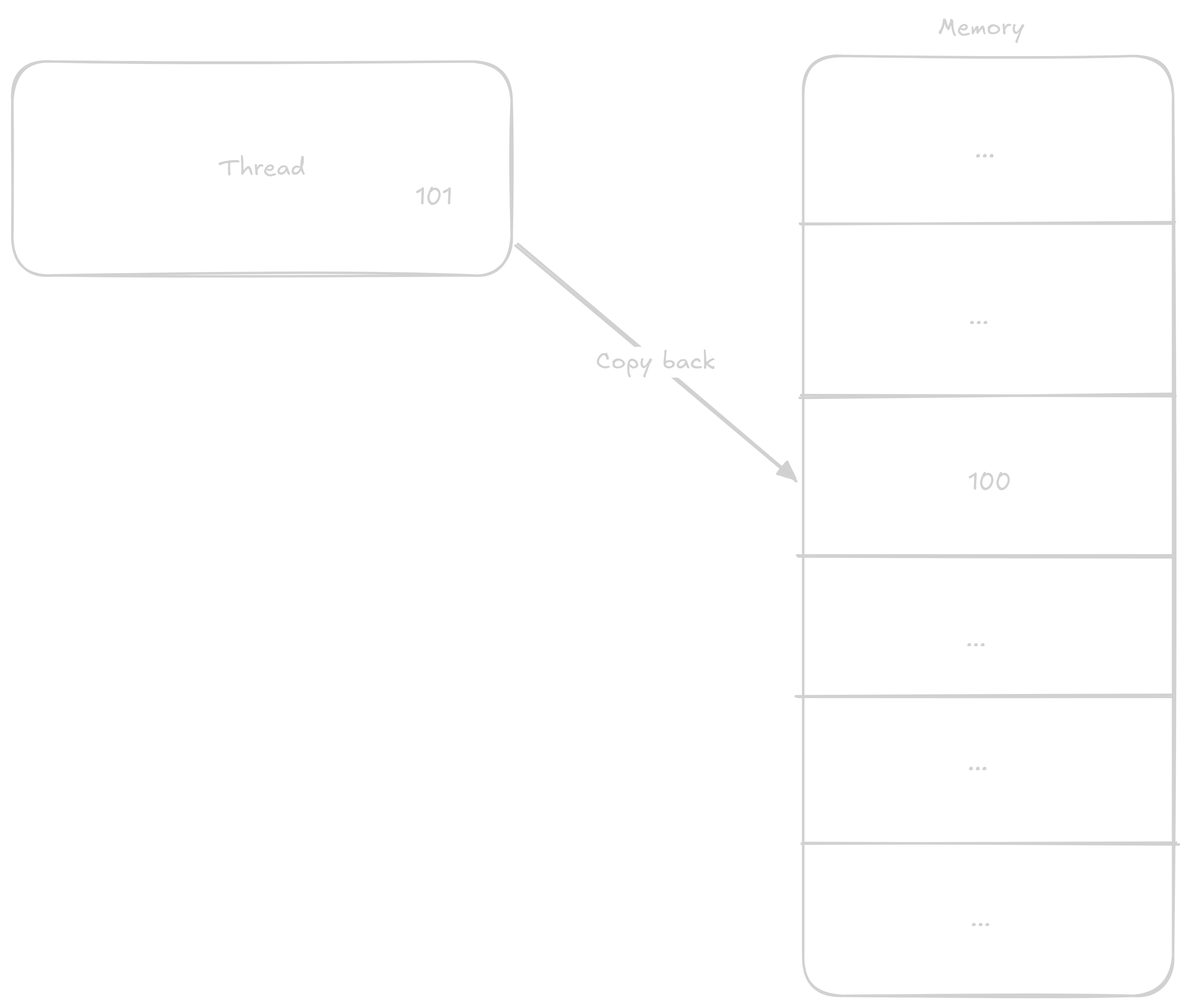
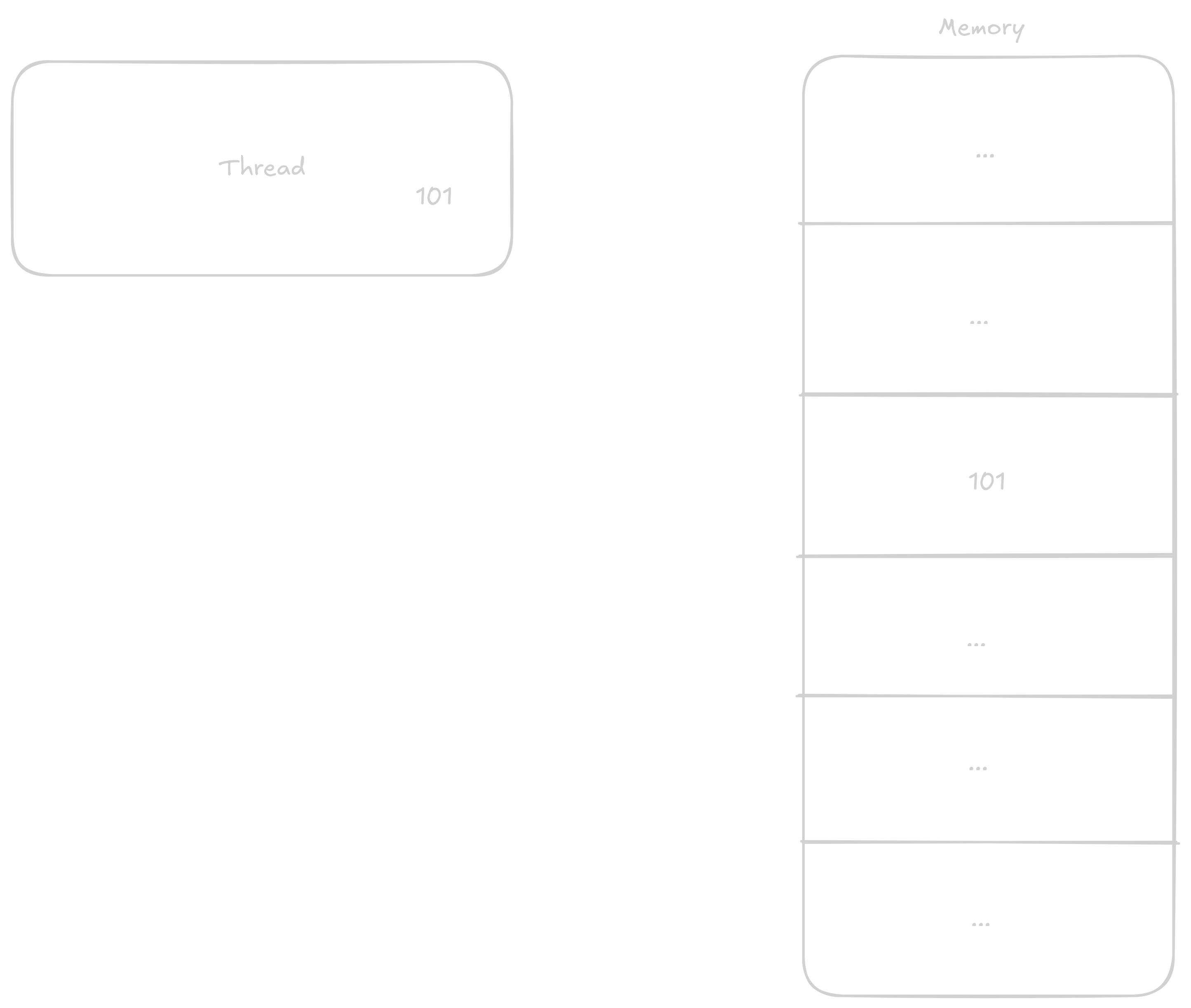
In the case that two threads will be adding to the variable at once, the steps can get mixed up something like this:
1 to the value1 to its now old value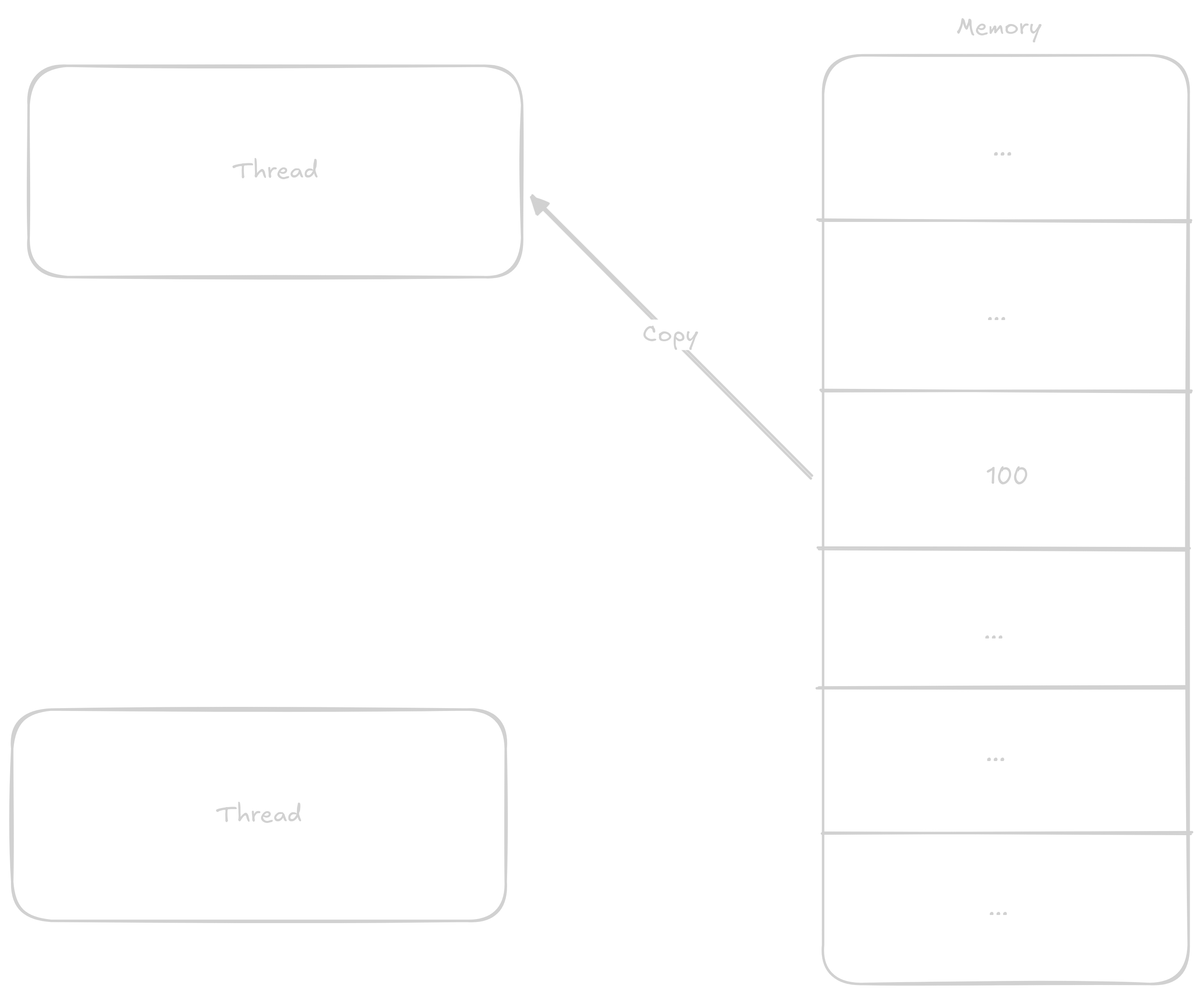
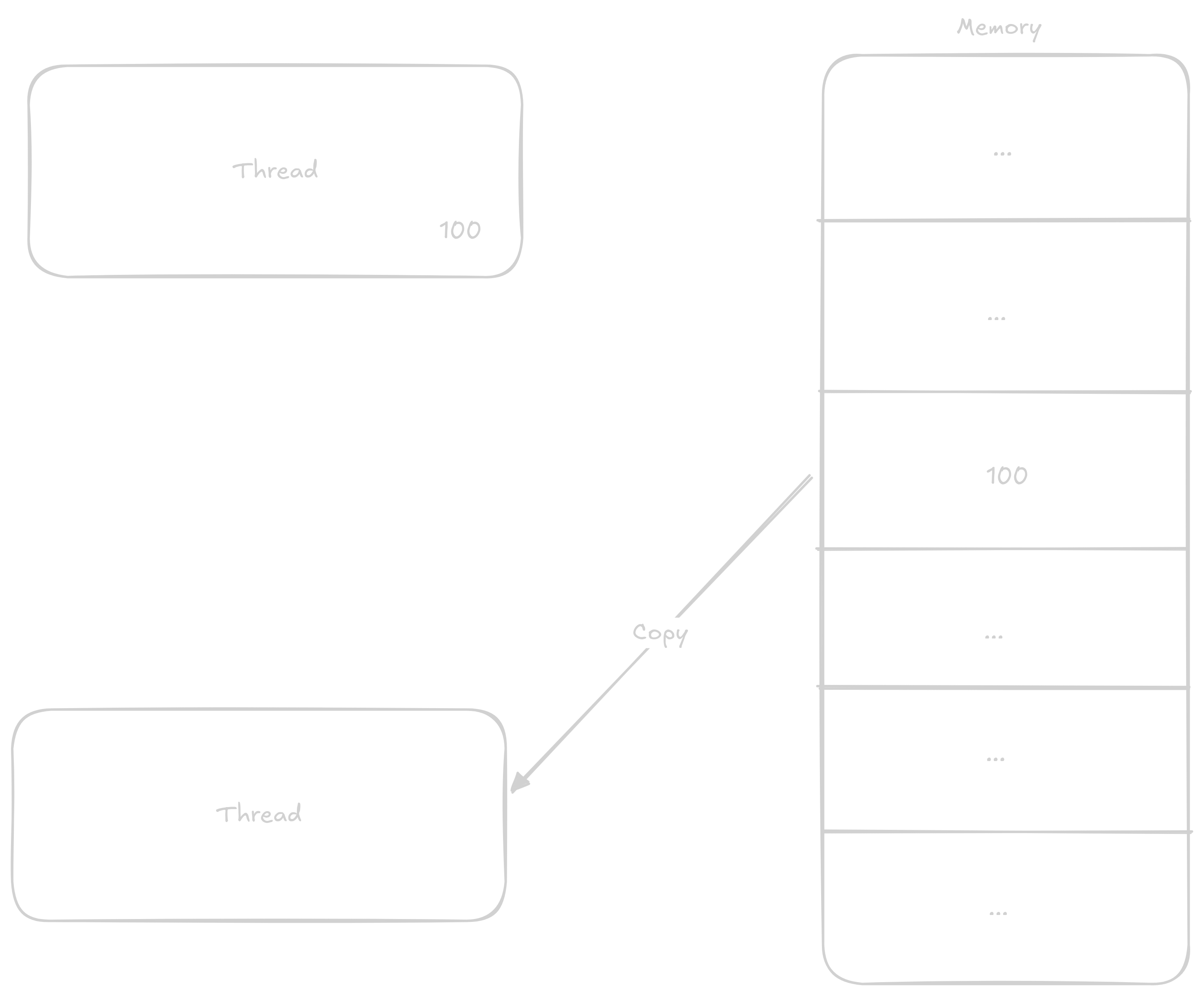
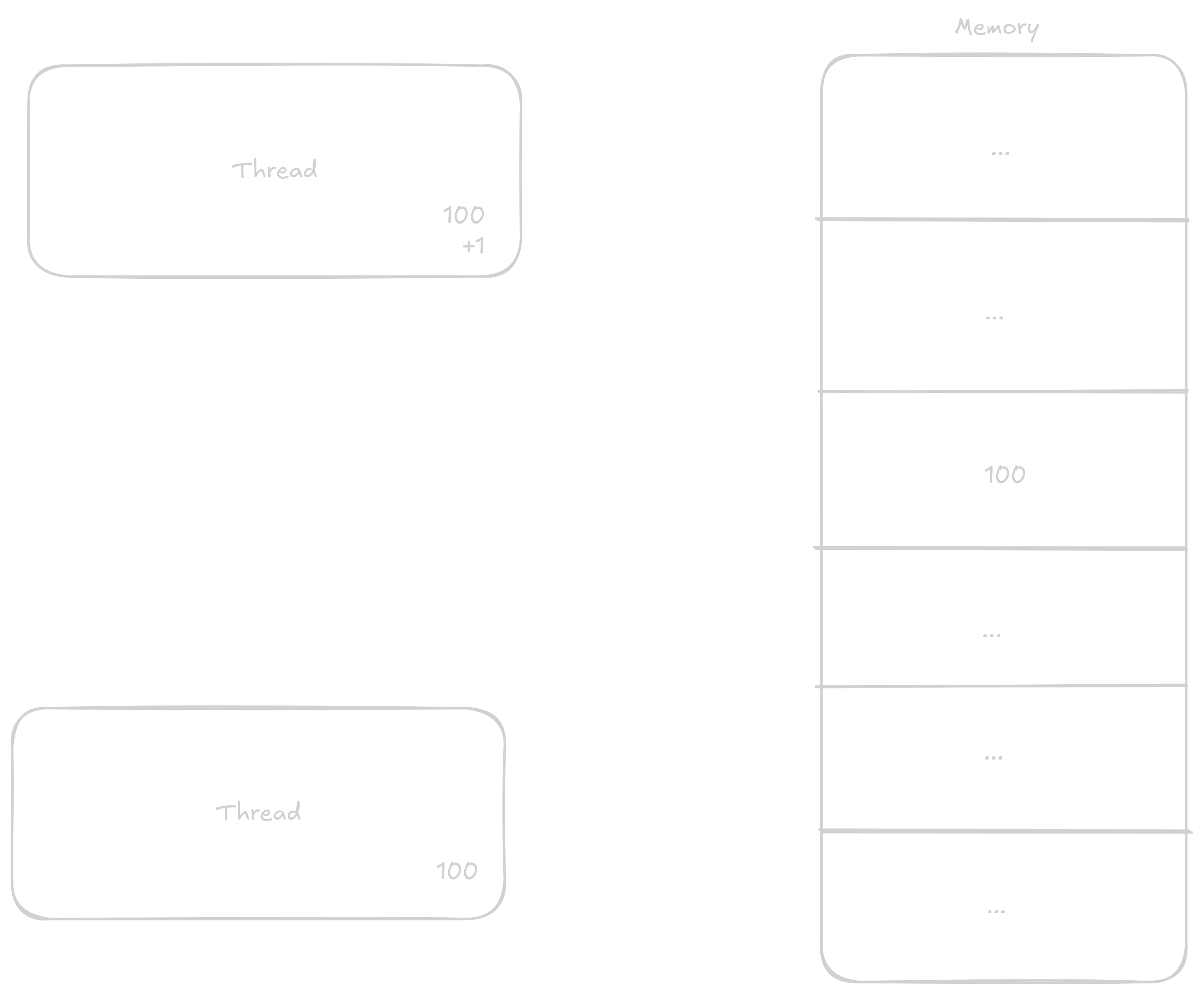
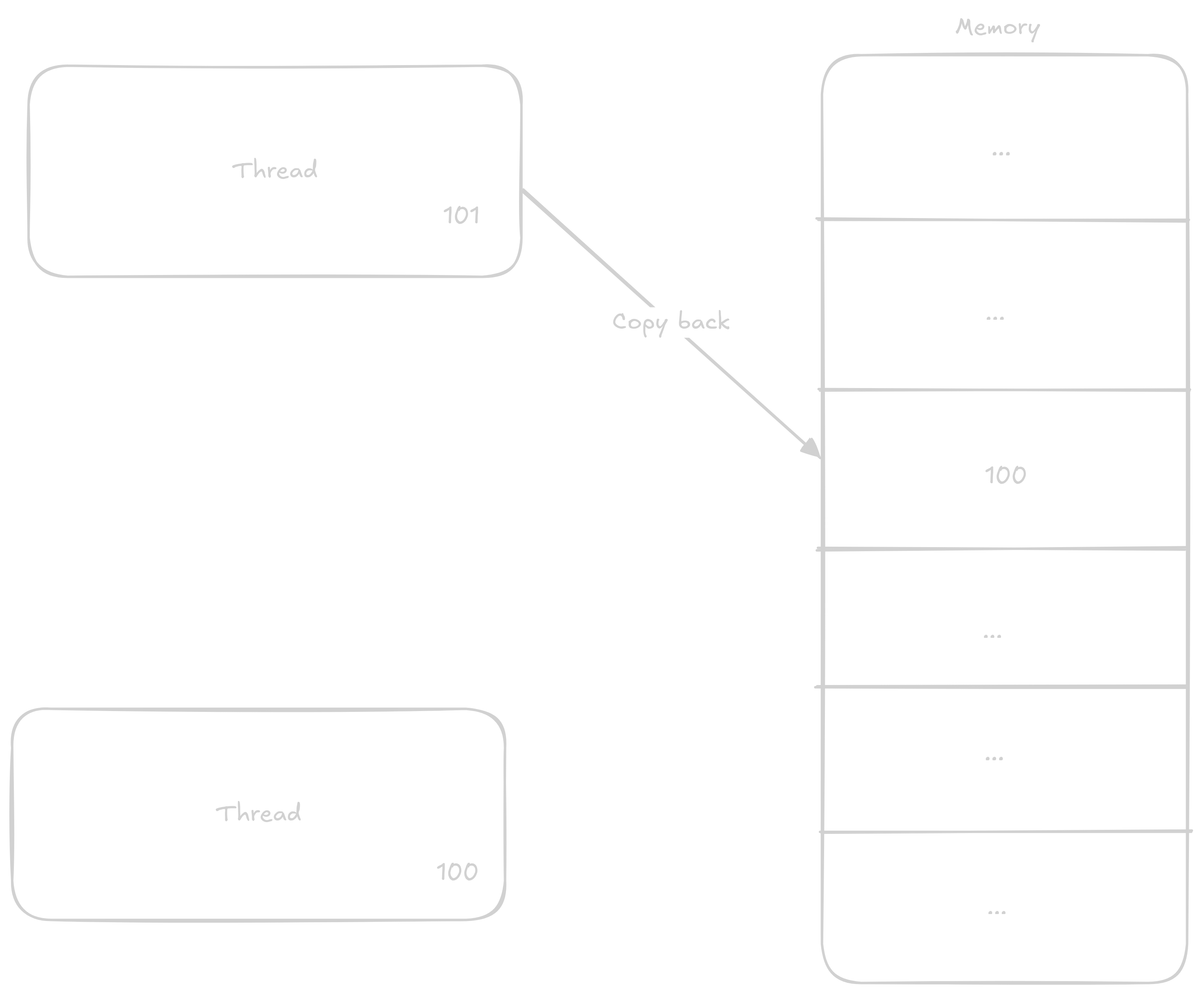
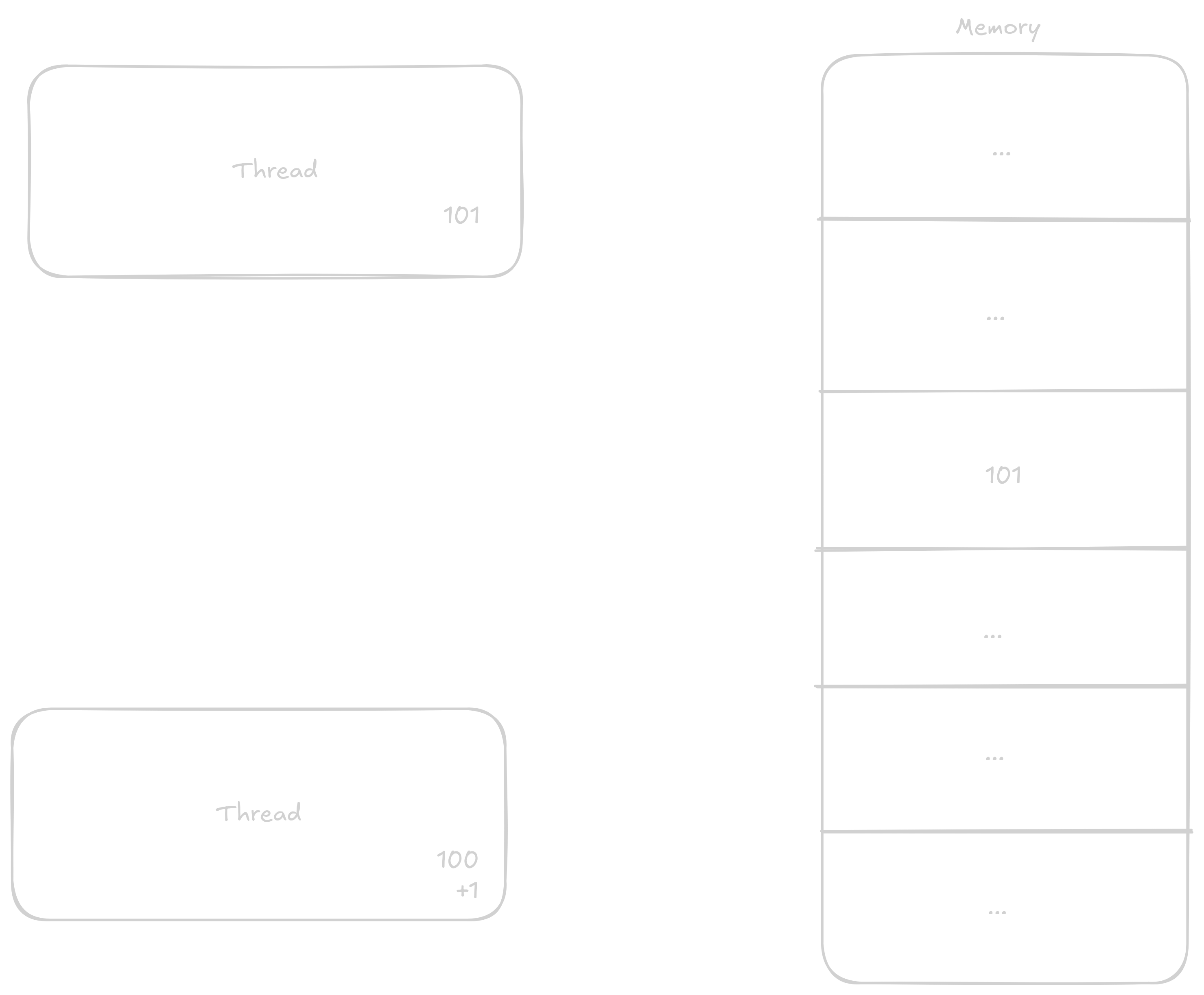
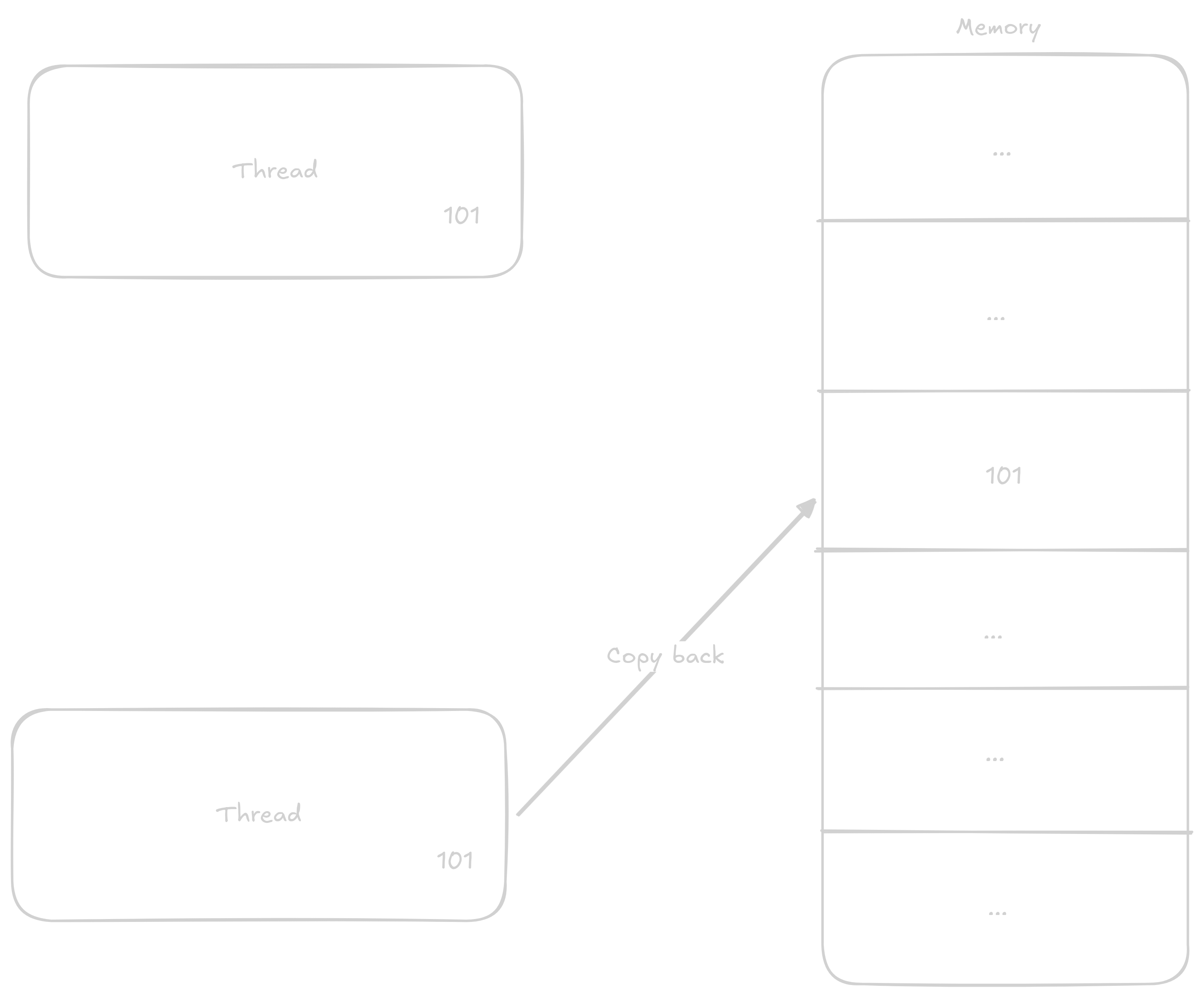
This way, even though two additions should have occurred, only one did.
Because of this, the result of the above program will be something like count = 100000, count = 137269, count = 98455, or again anything in between.
We call this problem a race condition. We’ll address how to avoid this problem in the next chapter.
These data structures allow us to share information between individual cores. This information is most often: You don’t have access to this resource, wait, or you have exclusive access to this resource. The principle of these structures is based on so-called atomic operations that execute all at once without anything being able to interrupt them.
The most common atomic operations are either read-modify-write or instructions that load a value from an address and then lock that address until they write to it. Both of these types work on the same principle - the processor records that everyone must wait if they want to do something with this address. Read-modify-write instructions load values, perform an operation on them, and store the value in one instruction, while the second type of operation lets the programmer do what they want with the values before they’re stored again.
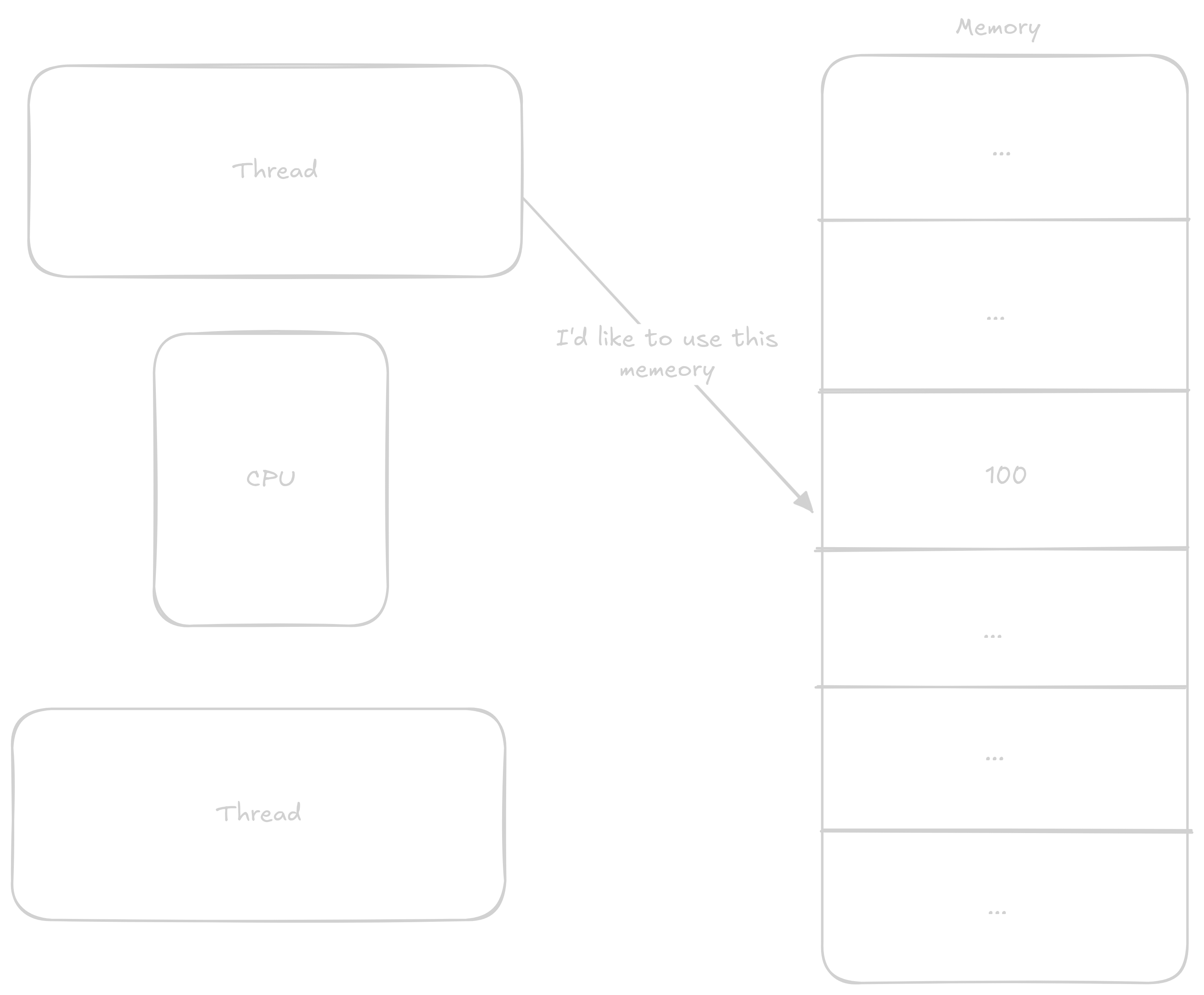
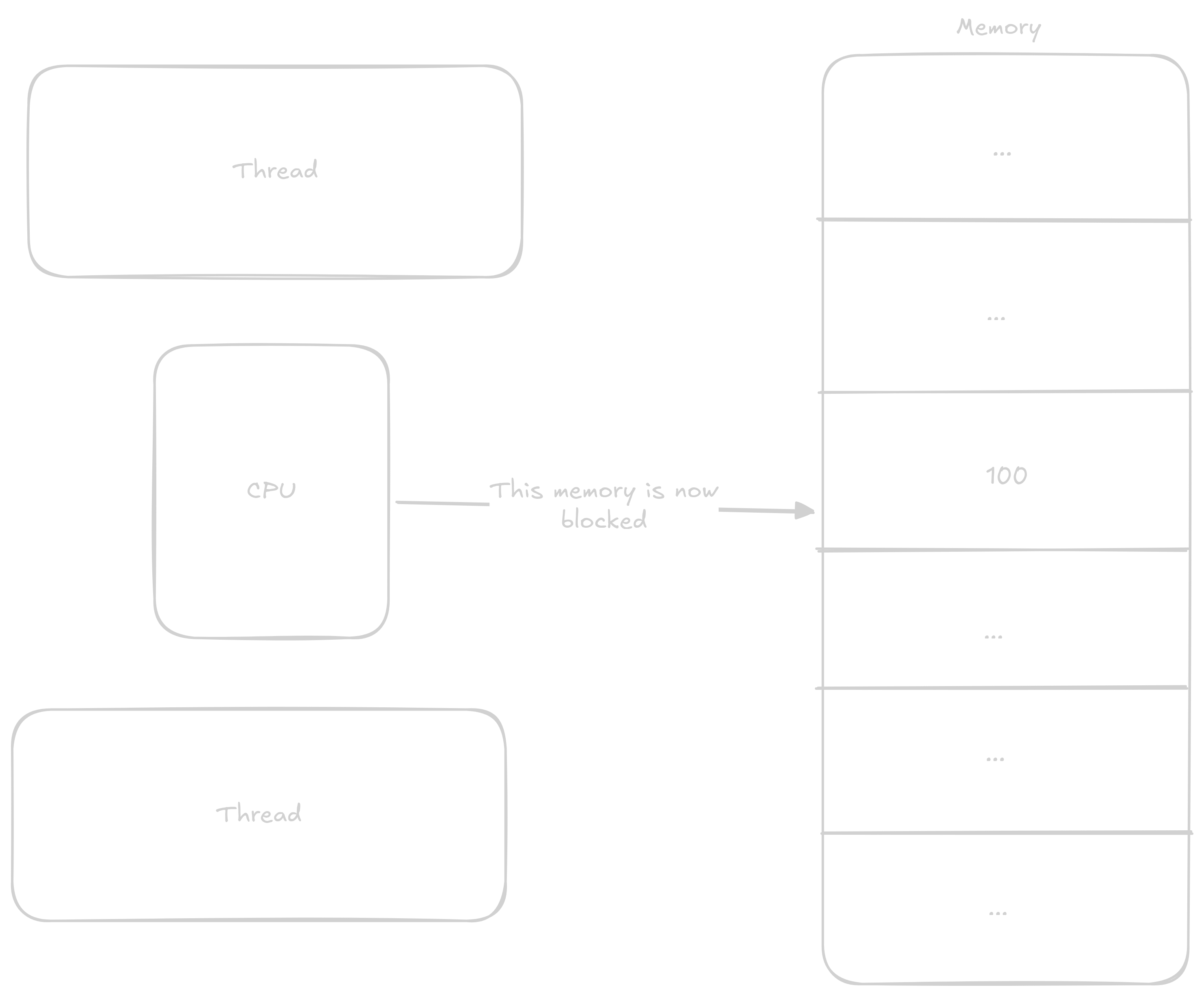
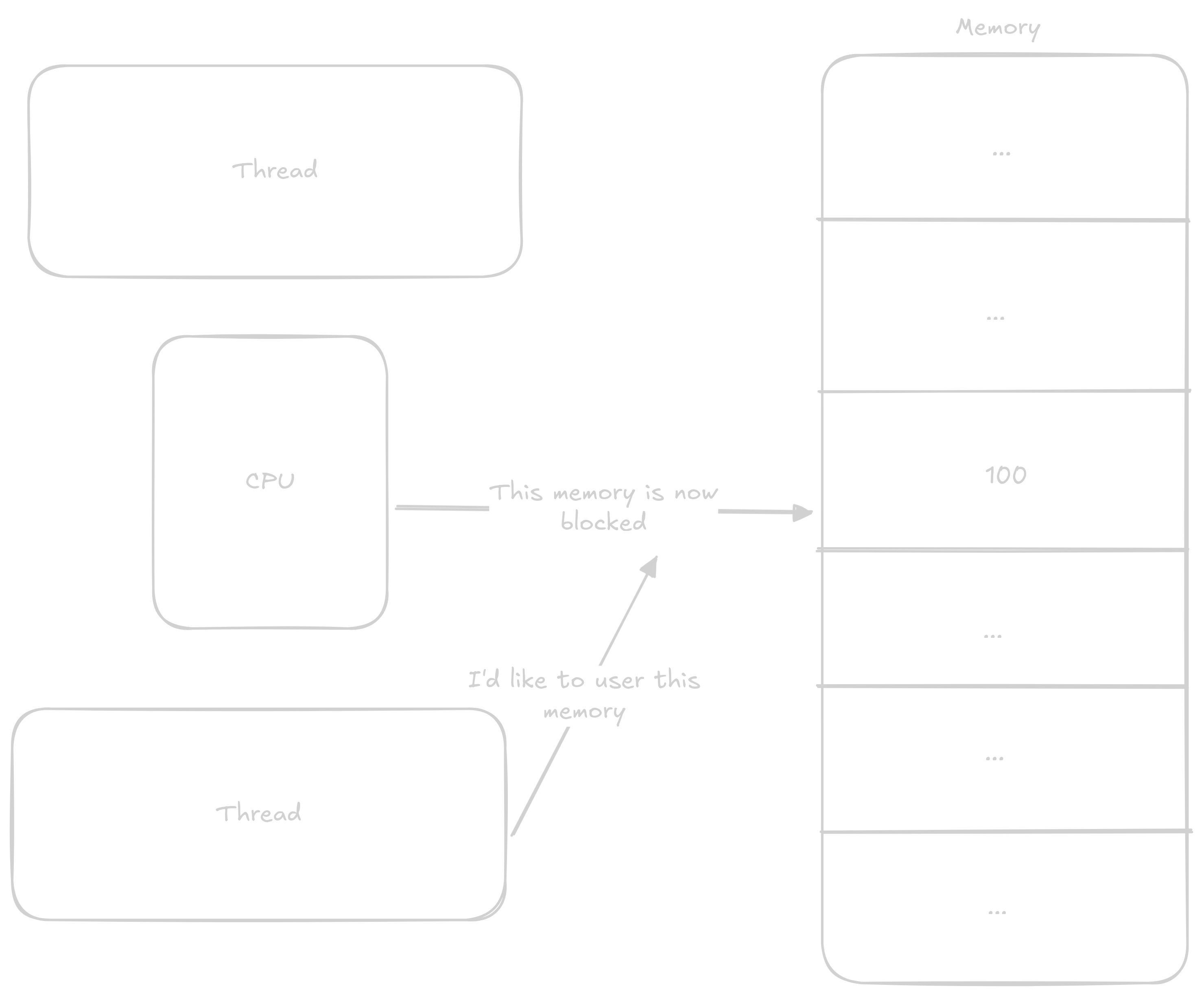
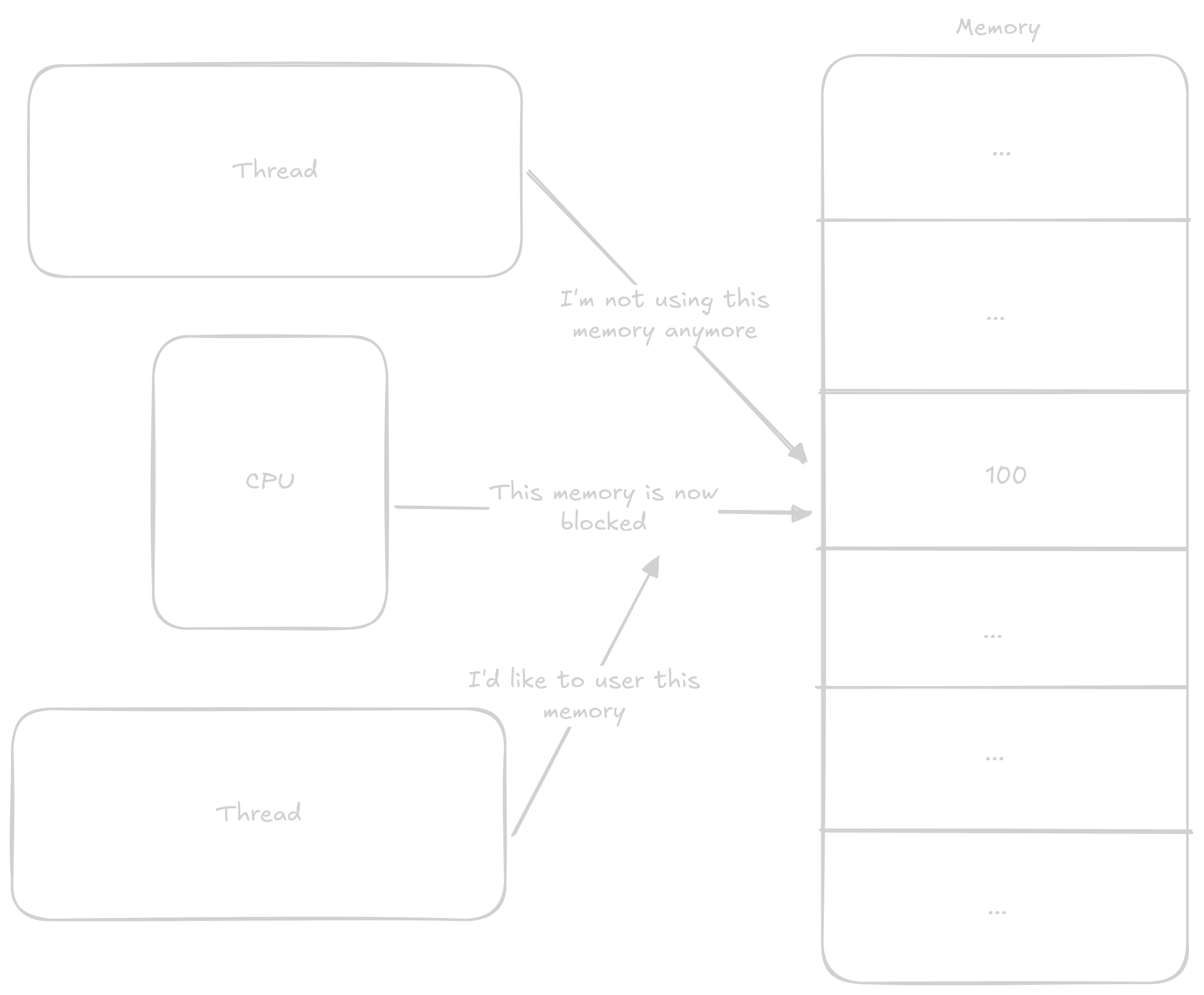
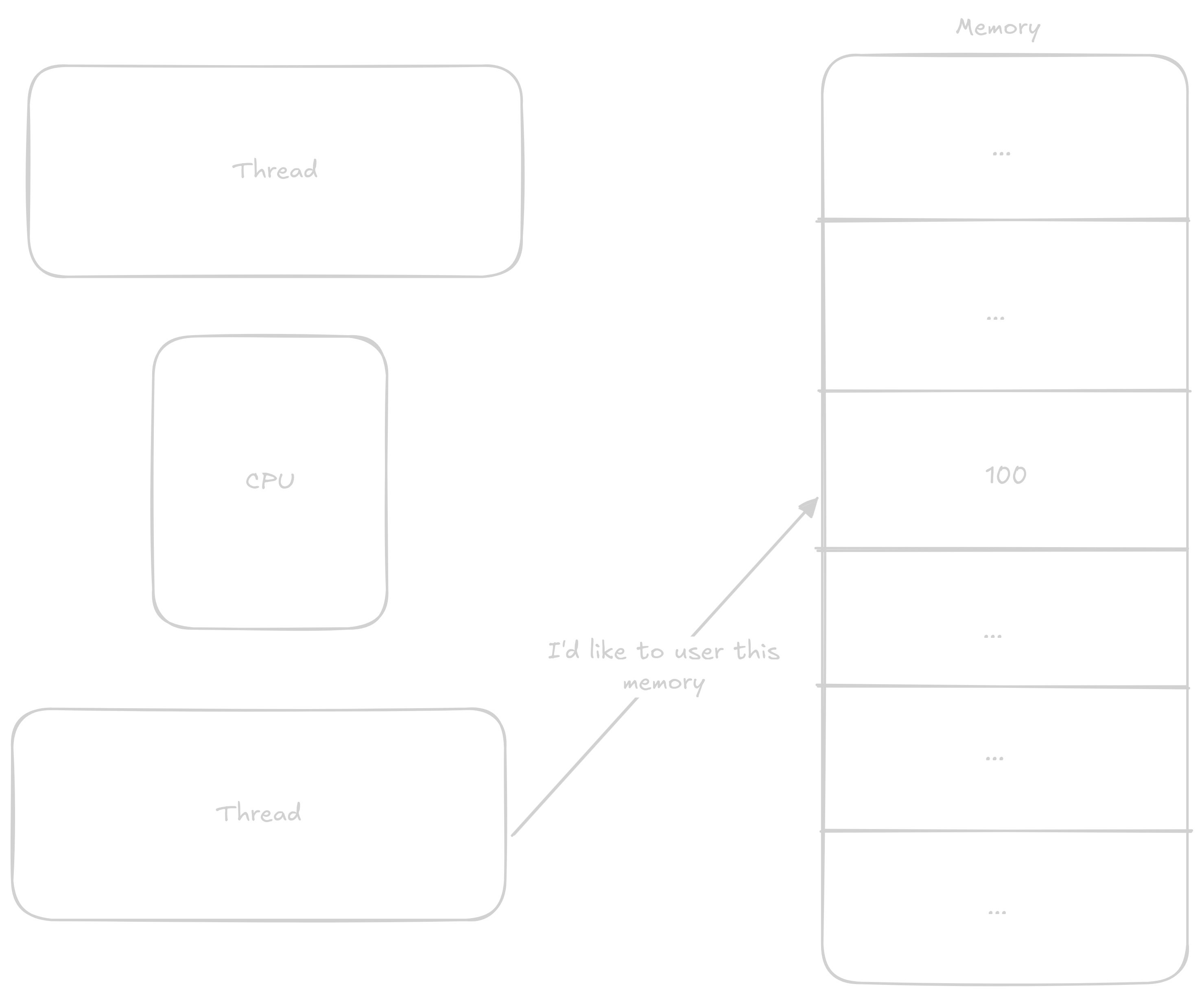
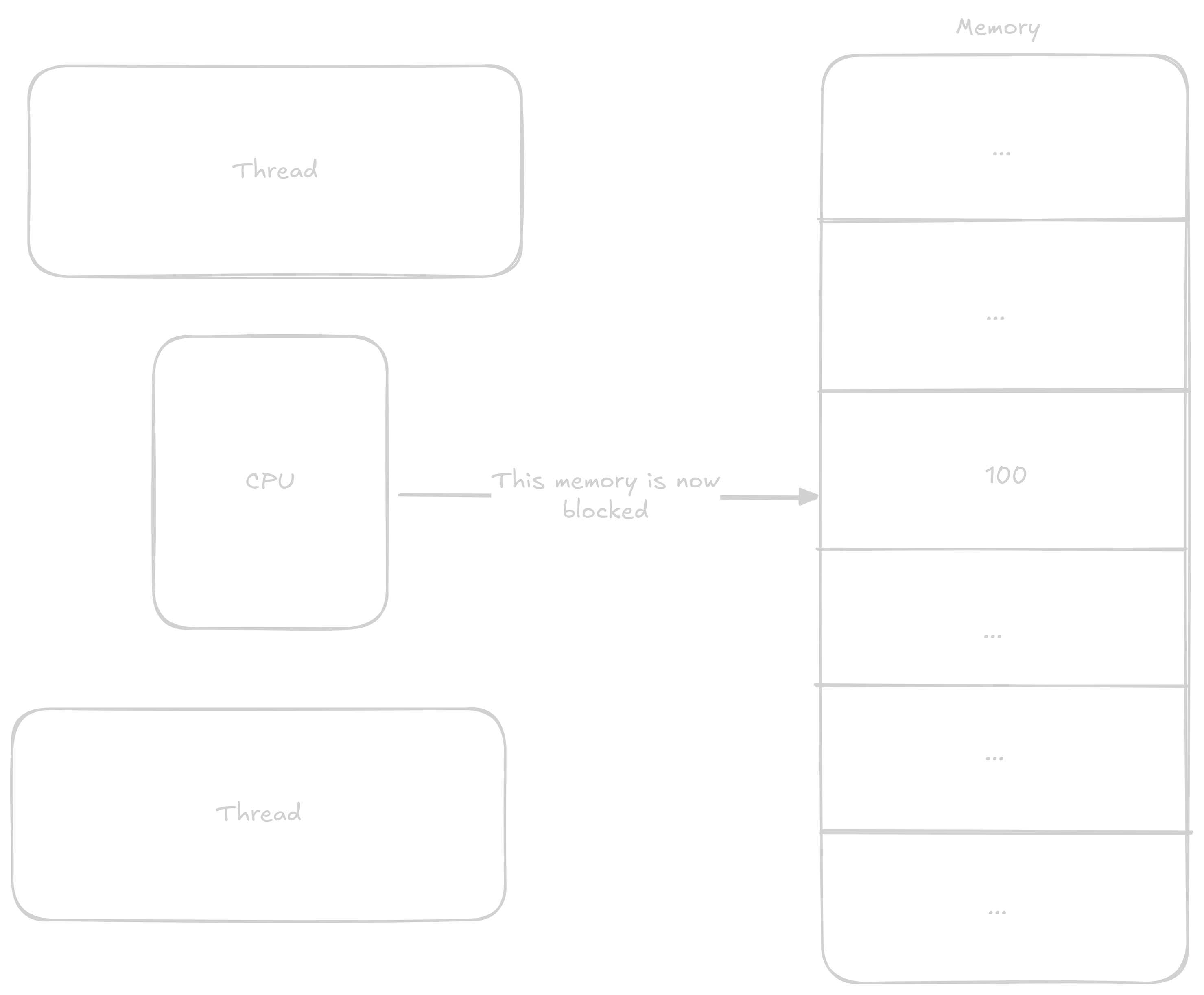
In the previous program where we were adding to counter, we could atomically add to the counter variable and thereby avoid the aforementioned race condition.
Such code would look like this:
#include <pthread.h>
#include <stdatomic.h>
#include <stdio.h>
// count will be of type atomic_int
atomic_int count = 0;
void *inc_count(void *arg) {
int i;
for (i = 0; i < 100000; i++) {
// here we atomically add 1 to the variable count
atomic_fetch_add(&count, 1);
}
return NULL;
}
int main() {
pthread_t t1, t2;
pthread_create(&t1, NULL, inc_count, NULL);
pthread_create(&t2, NULL, inc_count, NULL);
pthread_join(t1, NULL);
pthread_join(t2, NULL);
printf("count = %d\n", count);
return 0;
}This code will always print count = 200000 because we have a processor-level guarantee that exactly one thread is always adding to the count variable.
Now let’s look at this code:
#include <pthread.h>
#include <stdatomic.h>
#include <stdio.h>
#include <string.h>
#define BUFFER_SIZE 200001
char buffer[BUFFER_SIZE];
atomic_int position = 0;
void *write_chars(void *arg) {
// cast and dereference argument from void pointer to char
char c = *(char *)arg;
for (int i = 0; i < 100000; i++) {
if (position < BUFFER_SIZE - 1) {
// insert character at current position
buffer[position] = c;
atomic_fetch_add(&position, 1);
}
}
return NULL;
}
int main() {
pthread_t t1, t2;
char c1 = 'A', c2 = 'B';
memset(buffer, 0, BUFFER_SIZE);
pthread_create(&t1, NULL, write_chars, &c1);
pthread_create(&t2, NULL, write_chars, &c2);
pthread_join(t1, NULL);
pthread_join(t2, NULL);
buffer[position] = '\0';
printf("Expected position: 200000\n");
printf("Actual position: %d\n", position);
int a_count = 0, b_count = 0, skipped_count = 0;
for (int i = 0; i < position; i++) {
if (buffer[i] == 'A')
a_count++;
else if (buffer[i] == 'B')
b_count++;
else if (buffer[i] == 0)
skipped_count++;
else
return 1;
}
printf("A's: %d, B's: %d, skipped: %d\n", a_count, b_count, skipped_count);
printf("Total characters written: %d\n", a_count + b_count);
return 0;
}Here we’re filling the buffer with the letter A from one thread and the letter B from another thread.
Even though we might expect the program to run correctly because we’re using atomic addition, we’ll again encounter our aforementioned enemy, the race condition.
This time the race condition occurs between these two lines:
buffer[position] = c;
atomic_fetch_add(&position, 1);The reason is that the operations happen in this order:
positionpositionpositionpositionBoth cores therefore write to the same position and then both add to position, thereby completely skipping one position.
The output of this program will therefore look something like this:
Expected position: 200000
Actual position: 200000
A's: 99358, B's: 99641, skipped: 1001
Total characters written: 198999position has the correct value because it’s always correctly atomically incremented, but due to the race condition described above, writes to some positions in buffer will be skipped.
Here we can see that this isn’t the best way to work with atomic operations and that we’ll need to create some more robust way to prevent race conditions.
Mutex or mutual exclusivity is a synchronization data structure that allows exactly one thread at a time to access a resource. If a second core wants to access this resource, it must wait until the first core “gives up” the resource.
A mutex has two main operations: lock and unlock (I’ll use these interchangeably). Lock either locks the mutex or waits until the mutex is unlocked and then locks it, and unlock simply unlocks the mutex.
In principle, we need to signal two states - locked and unlocked, which can be done with one number that will have the value 1 or 0.
typedef struct {
atomic_int flag;
} simple_mutex;This is all that’s needed to model a mutex.
Now we’ll use several new constructs from the stdatomic.h library.
The first is atomic_init() with which we initialize the mutex:
void simple_mutex_init(simple_mutex *mtx) {
// set initial value of flag to 0
// 0 indicates that the mutex is released
atomic_init(&mtx->flag, 0);
}To lock the mutex, we must use the somewhat more complicated atomic_exchange().
void simple_mutex_lock(simple_mutex *mtx) {
while (atomic_exchange(&mtx->flag, 1) == 1) {
// Spin
}
}Atomic exchange returns the value that was originally stored at the address.
What we’re doing here is waiting until the previous value of flag is not equal to 1 (that is, it equals 0).
The moment the previous value of flag is not equal to 1 means that another thread released the mutex and we immediately locked it again using exchange, and the loop ends.
Finally, unlocking is simply storing 0 into flag using atomic_store().
void simple_mutex_unlock(simple_mutex *mtx) {
atomic_store(&mtx->flag, 0);
}You can download the complete source code of the mutex here and the header file here.
Now that we have a mutex, we can use it to fix the race condition in the previous program.
#include "simple_mutex.h" // [!code ++]
#include <pthread.h>
#include <stdio.h>
#include <string.h>
#define BUFFER_SIZE 200001
char buffer[BUFFER_SIZE];
int position = 0; // [!code ++]
simple_mutex mtx; // [!code ++]
void *write_chars(void *arg) {
// cast and dereference argument from void pointer to char
char c = *(char *)arg;
for (int i = 0; i < 100000; i++) {
// at this point we lock the mutex and buffer and position can be accessed // [!code ++]
// only by this thread // [!code ++]
simple_mutex_lock(&mtx); // [!code ++]
if (position < BUFFER_SIZE - 1) {
// insert character at current position
buffer[position] = c;
position++; // [!code ++]
}
simple_mutex_unlock(&mtx); // [!code ++]
}
return NULL;
}
int main() {
pthread_t t1, t2;
char c1 = 'A', c2 = 'B';
// mutex initialization // [!code ++]
simple_mutex_init(&mtx); // [!code ++]
memset(buffer, 0, BUFFER_SIZE);
pthread_create(&t1, NULL, write_chars, &c1);
pthread_create(&t2, NULL, write_chars, &c2);
pthread_join(t1, NULL);
pthread_join(t2, NULL);
buffer[position] = '\0';
printf("Expected position: 200000\n");
printf("Actual position: %d\n", position);
int a_count = 0, b_count = 0, skipped_count = 0;
for (int i = 0; i < position; i++) {
if (buffer[i] == 'A')
a_count++;
else if (buffer[i] == 'B')
b_count++;
else if (buffer[i] == 0)
skipped_count++;
else
return 1;
}
printf("A's: %d, B's: %d, skipped: %d\n", a_count, b_count, skipped_count);
printf("Total characters written: %d\n", a_count + b_count);
return 0;
}Now the program prints the expected output:
Expected position: 200000
Actual position: 200000
A's: 100000, B's: 100000, skipped: 0
Total characters written: 200000Thanks to the mutex, writing to buffer and incrementing position always happen at once without another thread being able to do anything at that moment.
These operations are always performed by exactly one thread, and all other threads must wait until the mutex is released before they can perform these operations.
If you want to use a mutex in a real program, it’s better to use the mutex directly from the pthread.h library.
The mutex in this library is better written and tested.
The above implementation of the mutex is suitable only for educational purposes.
#include <pthread.h>
int main() {
pthread_mutex_t mtx;
pthread_mutex_init(&mtx, NULL)
pthread_mutex_lock(&mtx);
pthread_mutex_unlock(&mtx);
pthread_mutex_destroy(&mtx);
}Mutexes are suitable for situations when multiple threads need to read and write to some resource, whether it’s a string or anything else. The advantage of a mutex is that it’s very simple to integrate into your code. Whenever you access a shared resource, you lock the mutex before access and unlock the mutex when you no longer need the resource.
The disadvantage of a mutex is that it’s very easy to use it incorrectly. A mutex effectively makes some part of the code sequential, and it’s easy to lose any speedup that multithreading could bring by adding a mutex in the wrong place.
A mutex is also not suitable to use when some threads only need to read the resource and only some need to write, or when writes are occasionally made and the rest of the time only reading occurs. In these cases, it’s more appropriate to use a different structure.
Read Write Lock or rwlock is a structure similar to a mutex with the difference that it allows an unlimited number of read accesses or one write access. This structure is suitable in situations when you don’t always need to write but often only reading will suffice.
There are several ways to model rwlock; I’ll show one of the simplest ways using two mutexes, but there are also ways using only one number. (Mutex is such a basic building block of other synchronization data structures)
One mutex will “guard” the reader count so that readers can be added and removed. The second mutex will be locked if there’s more than one reader or exactly one writer.
typedef struct {
int readers;
pthread_mutex_t readers_lock;
pthread_mutex_t writer_lock;
} simple_rwlock;First we must initialize the rwlock, during which we initialize the mutexes from the pthread.h library and set readers to 0.
void simple_rwlock_init(simple_rwlock *rw) {
rw->readers = 0;
pthread_mutex_init(&rw->readers_lock, NULL);
pthread_mutex_init(&rw->writer_lock, NULL);
}Rwlock has two lock and two unlock operations. One set of lock/unlock is for read operations and another for write operations.
Reader lock adds a reader and prevents writers from being created.
void simple_rwlock_rlock(simple_rwlock *rw) {
// Lock mutex to avoid race condition when modifying readers value
pthread_mutex_lock(&rw->readers_lock);
rw->readers++;
if (rw->readers == 1) {
// if this is the first reader, we lock writer lock
// In case a writer has locked this lock in the meantime,
// the mutex will wait here until it's released again.
pthread_mutex_lock(&rw->writer_lock);
}
// release reader mutex again so more readers can be added
pthread_mutex_unlock(&rw->readers_lock);
}Reader unlock doesn’t differ much and mainly undoes the work of lock (I know, stating the obvious).
void simple_rwlock_runlock(simple_rwlock *rw) {
// just like with rlock, lock mutex to avoid race condition
pthread_mutex_lock(&rw->readers_lock);
rw->readers--;
if (rw->readers == 0) {
// if the last reader is removed, release writer lock
// because it's safe to write
pthread_mutex_unlock(&rw->writer_lock);
}
pthread_mutex_unlock(&rw->readers_lock);
}Writer has significantly simpler operations.
It just needs to lock the writer lock, which will be unlocked if there are 0 readers and writers, and whose locking prevents the creation of both new readers and writers.
void simple_rwlock_wlock(simple_rwlock *rw) {
// writer lock is locked while someone is reading
// while this mutex is locked, it's not possible to add readers
pthread_mutex_lock(&rw->writer_lock);
}Unlock then simply unlocks the writer lock.
void simple_rwlock_wunlock(simple_rwlock *rw) {
// after completing the write, release writer lock
pthread_mutex_unlock(&rw->writer_lock);
}Just like with mutex, this implementation is only for educational purposes - use the implementation from pthread.h
#include <pthread.h>
int main()
{
pthread_rwlock_t rwlock;
pthread_rwlock_init(&rwlock, NULL);
pthread_rwlock_rdlock(&rwlock);
pthread_rwlock_unlock(&rwlock);
pthread_rwlock_wrlock(&rwlock);
// here only one type of unlock is needed because rwlock can determine
// whether it's necessary to release read lock or writer lock
pthread_rwlock_unlock(&rwlock);
pthread_rwlock_destroy(&rwlock);
return 0;
}As already mentioned above, rwlock is suitable for places where you often need to read and sometimes write. Such systems include, for example, caches, configuration managers, or databases.
A close look at multithreading and synchronization data structures